LOAF is a large-scale overhead fisheye dataset for person detection and localization. It consists of over 70 videos, with more than 42K frame images, 448K person-detection annotations as well as corresponding location information.
Features
Distinguished from most other datasets, LOAF
adopts a vertical downward overhead approach using fisheye cameras, fixed at a height of 2.5 to 4
meters, providing a 360° panoramic view.
Collection
We capture 75 fisheye image sequences in 45
realistic scenarios as the raw data pool. The recorded sequences span 14 hrs; the image resolution is
2952×2952 pixels, and the frame rate is 10∼20 fps. Eventually, 42,942 images, sampled at 1 fps, are collected
to construct our LOAF dataset.
Person Detection
We instead label each person through a radius-aligned rectangular box. Such representation is favored as it: i) allows unique groundtruth box assignment; ii) fits
well radially- oriented human bodies presented in fisheye images; and iii) better corresponds to
the actual position of human on the image plane, facilitating physical localization.
Finally, around 448K human box annotations are obtained.
Person Localization
For each annotated box, we can easily infer the standing position of the person in the image by
utilizing the radius-align feature, and then use the mapping relationship to project each person
into real-world space to obtain their location information.
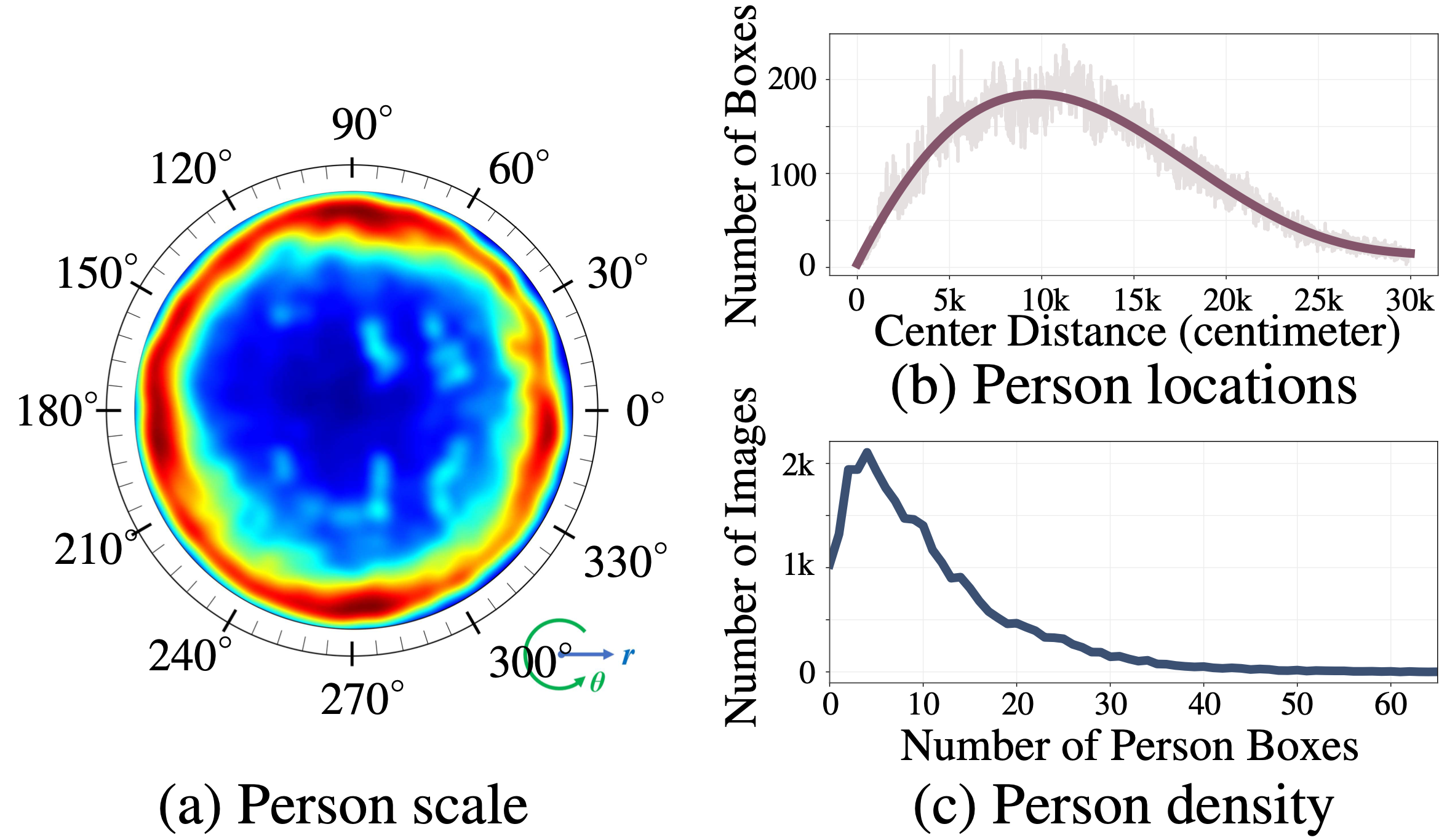
Large-scale
LOAF has 42942 fisheye images with more than 448K person boxes. Moreover,
LOAF data are captured by an advanced fisheye camera, which is capable of covering a larger area
(200∼300㎡) with higher pedestrian density (2∼65 persons per scene, 10.5 in average). This makes
LOAF the largest overhead fisheye dataset in terms of the total number of pedestrian and scene
categories.
High Diversity
Existing datasets limit in data diversities, i.e., only containing very few indoor scenes (2∼14) and completely missing outdoor
scenarios. In contrast, LOAF involves 51 realistic scenes, including 11 indoor scenes (e.g., lab,
office, library, classroom) and 40 outdoor scenes (e.g., street, playground, parking lot, square).
The recorded data cover four seasons under different illumi nation (e.g., morning, noon, afternoon)
and weather (e.g., sunny, rain, snow) conditions, and involve vast variance of human pose (e.g.,
walking, standing, and sitting), scale, location, and density Thus our dataset better reflects the
distribution in real-world surveillance scenarios.
Rich and Positioning-aware Annotation
LOAF is provided with rich ground-truths for detection, localization, and scene attribute, which lays
a solid foundation for fisheye camera based human-centric analysis. The radius-aligned human-box representation
is adopted during our annotation. Compared with human head center based point annotation and human-aligned
person-boxes used in previous datasets, radius-aligned human-boxes are more suitable for the position task.
Top